

Yandex est le moteur de recherche avec une part de marché majoritaire en Russie et le quatrième moteur de recherche au monde.
Le 27 janvier 2023, il a subi ce qui est sans doute l’une des plus importantes fuites de données qu’une entreprise de technologie moderne ait subie depuis de nombreuses années, mais il s’agit de la deuxième fuite en moins d’une décennie.
En 2015, un ancien employé de Yandex a tenté de vendre le code du moteur de recherche de Yandex sur le marché noir pour environ 30 000$.
La fuite initiale en janvier de cette année a révélé 1 922 facteurs de classement, dont plus de 64 % ont été répertoriés comme inutilisés ou obsolètes (remplacés et mieux évités).
Cette fuite n’était que le fichier étiqueté kernel, mais au fur et à mesure que la communauté SEO et moi-même avons approfondi nos recherches, davantage de fichiers ont été trouvés qui, combinés, contiennent environ 17 800 facteurs de classement.

Yandex, comme Google, a toujours été public avec ses mises à jour et modifications d’algorithmes, et ces dernières années, comment il a adopté l’apprentissage automatique.
Les mises à jour notables des deux ou trois dernières années incluent :
- Vega (qui a doublé la taille de l’index).
- Mimétisme (pénaliser les faux sites Web se faisant passer pour des marques).
- Mise à jour Y1 (présentant YATI).
- Mise à jour Y2 (fin 2022).
- Adoption d’IndexNow.
- Un nouveau déploiement et une mise à jour supposée du filtre PF.
Sur une note personnelle, cette fuite de données est comme un deuxième Noël.
Depuis janvier 2020, je gère un site Web d’actualités SEO en tant que passe-temps dédié à la couverture de Yandex SEO et de l’actualité de la recherche en Russie avec plus de 600 articles, c’est donc probablement l’événement phare du site de passe-temps.
J’ai également pris la parole à deux reprises lors de la conférence Optimization, la plus grande conférence SEO en Russie.
C’est également un bon test pour voir à quel point les déclarations publiques de Yandex correspondent aux secrets de la base de code.
En 2019, en travaillant avec l’équipe de relations publiques de Yandex, j’ai pu interviewer des ingénieurs de leur équipe de recherche et j’ai posé un certain nombre de questions provenant de la communauté SEO occidentale au sens large.
Vous pouvez lire l’interview avec l’équipe de recherche Yandex ici .
Alors que Yandex est principalement connu pour sa présence en Russie, le moteur de recherche est également présent en Turquie, au Kazakhstan et en Géorgie.
La fuite de données était considérée comme politiquement motivée et les actions d’un employé voyou, et contient un certain nombre de fragments de code du référentiel monolithique de Yandex, Arcadia.
Dans les 44 Go de données divulguées, il existe des informations relatives à un certain nombre de produits Yandex, notamment Search, Maps, Mail, Metrika, Disc et Cloud.
Ce que Yandex a à dire
Au moment où j’écris cet article (31 janvier), Yandex a déclaré publiquement que :
le contenu de l’archive (leaked code base) correspond à la version obsolète du référentiel – elle diffère de la version actuelle utilisée par nos services
Et:
Il est important de noter que les fragments de code publiés contiennent également des algorithmes de test qui ont été utilisés uniquement dans Yandex pour vérifier le bon fonctionnement des services.
La quantité de cette base de code qui est activement utilisée est donc discutable.
Yandex a également révélé qu’au cours de leur enquête et de leur audit, ils ont trouvé un certain nombre d’erreurs qui violent leurs propres principes internes, il est donc probable que des parties de ce code divulgué (qui sont actuellement utilisées) puissent changer dans un proche avenir.
Classification des facteurs
Yandex classe ses facteurs de classement en trois catégories.
Cela a été décrit dans la documentation publique de Yandex depuis un certain temps, mais je pense qu’il vaut la peine d’être inclus ici car cela nous aide mieux à comprendre la fuite du facteur de classement.
- Facteurs statiques – Facteurs directement liés au site Web, par exemple les backlinks entrants, les liens internes entrants, les en-têtes, le ratio d’annonces.
- Facteurs dynamiques – Facteurs liés à la fois au site Web et à la requête de recherche, par exemple la pertinence du texte, les inclusions de mots clés, TF*IDF .
- Facteurs liés à la recherche de l’ utilisateur – Facteurs liés à la requête de l’utilisateur, par exemple où se trouve l’utilisateur, langue de la requête, modificateurs d’intention.
Les facteurs de classement dans le document sont balisés pour correspondre à la catégorie correspondante, avec TG_STATIC et TG_DYNAMIC, puis TG_QUERY_ONLY, TG_QUERY, TG_USER_SEARCH et TG_USER_SEARCH_ONLY.
Apprentissages de Yandex sur les fuites jusqu’à présent
À partir des données jusqu’à présent, voici quelques-unes des affirmations et des apprentissages que nous avons pu faire.
Il y a tellement de données dans cette fuite qu’il est très probable que nous trouverons de nouvelles choses et établirons de nouvelles connexions dans les prochaines semaines.
Ceux-ci inclus:
- PageRank (une forme de).
- À un moment donné, Yandex a utilisé TF * IDF.
- Yandex utilise toujours des méta-mots-clés , qui sont également mis en évidence dans leur documentation .
- Yandex a des facteurs spécifiques pour les sujets médicaux, juridiques et financiers ( YMYL ).
- Ils utilisent une forme de score de qualité de page, mais cela est connu ( score ICS ).
- Les liens des sites Web de haute autorité ont un impact sur les classements.
- Rien de nouveau ne suggère que Yandex puisse explorer JavaScript en dehors des processus déjà documentés publiquement.
- Les erreurs de serveur et les erreurs 4xx excessives peuvent avoir un impact sur le classement.
- L’heure de la journée est prise en compte comme facteur de classement.
Ci-dessous, j’ai développé d’autres affirmations et enseignements tirés de la fuite.
Dans la mesure du possible, j’ai également lié ces facteurs de classement divulgués aux mises à jour de l’algorithme et aux annonces qui les concernent, ou là où on nous a dit qu’ils avaient un impact.
MatrixNet
MatrixNet est mentionné dans quelques-uns des facteurs de classement et a été annoncé en 2009, puis remplacé en 2017 par Catboost , qui a été déployé dans la sphère des produits Yandex.
Cela ajoute encore plus de validité aux commentaires provenant directement de Yandex et de l’un des auteurs du facteur DenPlusPlus (Den Raskovalov) selon lequel il s’agit en fait d’un référentiel de code obsolète.
Introduit à l’origine comme un nouvel algorithme de base qui prenait en considération des milliers de facteurs de classement et des pondérations attribuées en fonction de l’emplacement de l’utilisateur, de la requête de recherche réelle et de l’intention de recherche perçue.
MatrixNet est généralement considéré comme un miroir de RankBrain de Google, ou vice versa étant donné que MatrixNet a été lancé 6 ans avant l’annonce de RankBrain.
MatrixNet a également été développé, ce qui n’est pas surprenant étant donné qu’il a maintenant 14 ans.
En 2016, Yandex a introduit l’algorithme Palekh qui utilisait des réseaux de neurones profonds pour mieux faire correspondre les documents (pages Web) et les requêtes, même s’ils ne contenaient pas les bons “niveaux” de mots-clés communs mais satisfaisaient les intentions de l’utilisateur.
Palekh était capable de traiter 150 pages à la fois, et en 2017 a été mis à jour avec la mise à jour Korolyov, qui prenait en compte une plus grande profondeur du contenu de la page, et pouvait travailler sur 200 000 pages à la fois.
Facteurs au niveau de l’URL et de la page
De la fuite, nous avons appris que Yandex prend en considération la construction d’URL, en particulier :
- La présence de chiffres dans l’URL.
- Le nombre de barres obliques finales dans l’URL (et si elles sont excessives).
- Le nombre de lettres majuscules dans l’URL est un facteur.
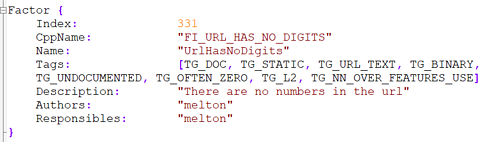
L’âge d’une page (âge du document) et la date de la dernière mise à jour sont également importants, et cela a du sens.
Outre l’âge du document et la dernière mise à jour, un certain nombre de facteurs dans les données sont liés à la fraîcheur, en particulier pour les requêtes liées à l’actualité.
Yandex utilisait auparavant des horodatages, en particulier non pas à des fins de classement mais à des fins de “réorganisation”, mais cela est maintenant classé comme inutilisé.
Dans la colonne obsolète figurent également l’utilisation de mots-clés dans l’URL. Yandex a précédemment mesuré que trois mots clés de la requête de recherche dans l’URL constitueraient un résultat “optimal”.
Liens internes et profondeur de crawl
Alors que Google a déclaré publiquement que pour eux, la profondeur d’exploration n’est pas explicitement un facteur de classement , Yandex semble avoir un morceau de code actif qui dicte que les URL accessibles depuis la page d’accueil ont un niveau d’importance “plus élevé”. .

Cela reflète la déclaration de John Mueller en 2018 selon laquelle Google donne “un peu plus de poids” aux pages trouvées à plus d’un clic de la page d’accueil.
Les facteurs de classement mettent également en évidence une pondération symbolique spécifique pour les pages Web qui sont « orphelines » dans la structure de liaison du site Web.
Clics et CTR
En 2011, Yandex a publié un article de blog expliquant comment le moteur de recherche utilise les clics dans le cadre de son classement et répond également aux désirs des professionnels du référencement de manipuler la métrique pour un gain de classement.
Les facteurs de clic spécifiques dans la fuite regardent des choses comme :
- Le ratio du nombre de clics sur l’URL, par rapport à tous les clics sur la recherche.
- Comme ci-dessus, mais ventilé par région.
- À quelle fréquence les utilisateurs cliquent-ils sur l’URL de la recherche ?
Manipulation des clics
La manipulation du comportement des utilisateurs, en particulier le “click-jacking”, est une tactique connue au sein de Yandex.
Yandex dispose d’un filtre, connu sous le nom de filtre PF, qui recherche et pénalise activement les sites Web qui se livrent à cette activité à l’aide de scripts qui surveillent les similitudes IP, puis les “actions de l’utilisateur” de ces clics, et l’impact peut être important.
La capture d’écran ci-dessous montre l’impact sur les sessions organiques (сессии) après avoir été pénalisé pour avoir imité les clics des utilisateurs.
-
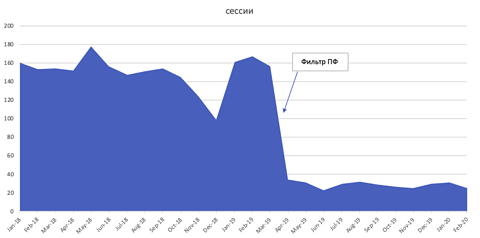 Image de Russian Search News, janvier 2023
Image de Russian Search News, janvier 2023
Comportement de l’utilisateur
Les conclusions sur le comportement des utilisateurs de la fuite sont parmi les découvertes les plus intéressantes.
La manipulation du comportement des utilisateurs est une tactique SEO courante que Yandex combat depuis des années. Lors de la conférence d’optimisation 2020, Mikhail Slevinsky, alors responsable des outils pour les webmasters de Yandex, a déclaré qu’ils (Yandex) faisaient de bons progrès dans la détection et la sanction de ce type de comportement.
Yandex pénalise la manipulation du comportement de l’utilisateur avec le même filtre PF utilisé pour lutter contre la manipulation CTR.
Temps de séjour
102 des facteurs de classement contiennent la balise TG_USERFEAT_SEARCH_DWELL_TIME et font référence à l’appareil, à la durée de l’utilisateur et au temps de séjour moyen de la page.
Tous sauf 39 de ces facteurs sont obsolètes.
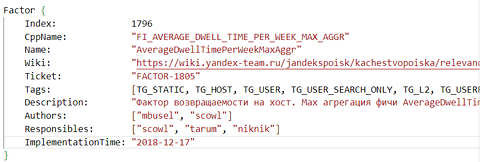
Bing a utilisé pour la première fois le terme temps de séjour dans un blog de 2011, et ces dernières années, Google a clairement indiqué qu’il n’utilisait pas le temps de séjour (ou des signaux d’interaction utilisateur similaires) comme facteurs de classement.
YMYL
YMYL (Your Money, Your Life) est un concept bien connu au sein de Google et n’est pas nouveau pour Yandex.
Dans la fuite de données, il existe des facteurs de classement spécifiques pour le contenu médical, juridique et financier – mais cela a notamment été révélé en 2019 lors de la conférence Yandex Webmaster lorsqu’ils ont annoncé la Proxima Search Quality Metric .
Utilisation des données Metrika
Six des facteurs de classement ont trait à l’utilisation des données de Metrika à des fins de classement. Cependant, l’un d’entre eux est marqué comme obsolète :
- Le nombre de visiteurs similaires du YandexBar (YaBar/Ябар).
- Le temps moyen passé sur les URL de ces mêmes visiteurs similaires.
- Le “core audience” des pages sur lesquelles il y a un compteur Metrika [obsolète].
- Le temps moyen qu’un utilisateur passe sur un hôte lorsqu’il y accède de manière externe (à partir d’un autre site sans recherche) à partir d’une URL spécifique.
- « Profondeur » moyenne (nombre de visites au sein de l’hôte) du séjour d’un utilisateur sur l’hôte lorsqu’il y accède de l’extérieur (à partir d’un autre site sans recherche) à partir d’une URL particulière.
- Si Metrika est installé ou non sur le domaine.
Dans Metrika, les données des utilisateurs sont traitées différemment.
Contrairement à Google Analytics, il existe un certain nombre de rapports axés sur la “fidélité” des utilisateurs combinant des mesures d’engagement sur le site avec la fréquence de retour, la durée entre les visites et la source de la visite.
Par exemple, je peux voir un rapport en un clic pour voir la répartition des visiteurs individuels du site :
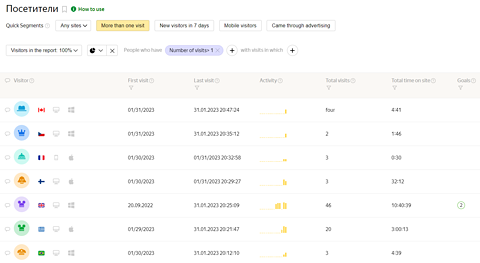
Metrika est également livré “prêt à l’emploi” avec des outils de carte thermique et l’enregistrement des sessions utilisateur, et ces dernières années, l’équipe Metrika a fait de bons progrès pour pouvoir identifier et filtrer le trafic des bots.
Avec Google Analytics, il y a un argument selon lequel Google n’utilise pas les données UA/GA4 à des fins de classement en raison de la facilité avec laquelle il est possible de modifier ou de casser le code de suivi, mais avec les compteurs Metrika, ils sont beaucoup plus linéaires et une grande partie des rapports sont immuables quant à la manière dont les données sont collectées.
Impact du trafic sur les classements
Après avoir examiné les données de Metrika en tant que facteur de classement ; ces facteurs confirment effectivement que le trafic direct et le trafic payant (achat d’annonces via Yandex Direct) peuvent avoir un impact sur les performances de recherche organique :
- Part des visites directes dans l’ensemble du trafic entrant.
- Part de trafic vert (c’est-à-dire visites directes). Bureau.
- Part de trafic vert (c’est-à-dire visites directes). Mobile.
- Trafic de recherche – transitions des moteurs de recherche vers le site.
- Part des visites sur le site non par des liens (mis à la main ou à partir de signets).
- Le nombre de visiteurs uniques.
- Part du trafic provenant des moteurs de recherche.
Facteurs d’actualité
Il existe un certain nombre de facteurs liés aux “actualités”, dont deux qui mentionnent directement Yandex.News.
Yandex.News était un équivalent de Google News mais a été vendu au réseau social russe VKontakte en août 2022, avec un autre produit Yandex “Zen”, il n’est donc pas clair si ces facteurs étaient liés à un produit qui n’est plus détenu ou exploité par Yandex, ou à la façon dont les sites Web d’actualités sont classés dans la recherche “normale”.
Importance des backlinks
Yandex a des algorithmes similaires pour lutter contre la manipulation des liens comme Google, et ce depuis le filtre Nepot en 2005.
En examinant les facteurs de classement des backlinks et certaines des spécificités des descriptions, nous pouvons supposer que les meilleures pratiques pour créer des liens pour Yandex SEO seraient de :
- Construisez des liens avec une fréquence plus naturelle et des quantités variables.
- Créez des liens avec des textes d’ancrage de marque et utilisez des mots-clés commerciaux.
- Si vous achetez des liens, évitez d’acheter des liens provenant de sites Web qui ont des sujets mixtes.
Vous trouverez ci-dessous une liste de facteurs liés aux liens qui peuvent être considérés comme des affirmations de meilleures pratiques :
- L’âge du backlink est un facteur.
- Pertinence des liens en fonction des sujets.
- Les backlinks construits à partir des pages d’accueil ont plus de poids que les pages internes.
- Les liens des 100 meilleurs sites Web par PR (PageRank) peuvent avoir un impact sur les classements.
- Pertinence des liens basée sur la qualité de chaque lien.
- Pertinence des liens, en tenant compte de la qualité de chaque lien et du sujet de chaque lien.
- Pertinence du lien, en tenant compte du caractère non commercial de chaque lien.
- Pourcentage de liens entrants avec des mots de requête.
- Pourcentage de mots de requête dans les liens (jusqu’à un synonyme).
- Les liens contiennent tous les mots de la requête (jusqu’à un synonyme).
- Dispersion du nombre de mots de requête dans les liens.
Cependant, certains facteurs liés aux liens sont des considérations supplémentaires lors de la planification, de la surveillance et de l’analyse des backlinks :
- Le rapport entre les “bons” et les “mauvais” backlinks vers un site Web.
- La fréquence des liens vers le site.
- Nombre de liens indésirables SEO entrants entre les hôtes.
La fuite de données a également révélé que le calculateur de spam de liens compte environ 80 facteurs actifs qui sont pris en compte, avec un certain nombre de facteurs obsolètes.
Cela soulève la question de savoir dans quelle mesure Yandex est capable de reconnaître les attaques SEO négatives, étant donné qu’il examine le rapport entre les bons et les mauvais liens, et comment il détermine ce qu’est un mauvais lien.
Une attaque SEO négative est également susceptible d’être un événement de lien de courte durée (haute fréquence) dans lequel un site gagnera involontairement un grand nombre de liens de mauvaise qualité, non thématiques et potentiellement sur-optimisés.
Yandex utilise des modèles d’apprentissage automatique pour identifier les réseaux de blogs privés (PBN) et les liens payants, et ils font la même hypothèse entre la vitesse des liens et la période pendant laquelle ils sont acquis.
Les liens généralement payants sont générés sur une plus longue période de temps, et ces modèles (y compris l’analyse du site d’origine du lien) sont ce que la mise à jour de Minusinsk (2015) a été introduite pour combattre.
Pénalités Yandex
Il existe deux facteurs de classement, tous deux obsolètes, nommés SpamKarma et Pessimization.
La pessimisation fait référence à la réduction du PageRank à zéro et correspond aux attentes de sanctions sévères de Yandex.
SpamKarma s’aligne également sur les hypothèses faites autour de Yandex pénalisant les hôtes et les individus, ainsi que les domaines individuels.
Publicité sur la page
Il existe un certain nombre de facteurs liés à la publicité sur la page, dont certains sont obsolètes (comme l’exemple de capture d’écran ci-dessous).

D’après la description, on ne sait pas exactement quel était le processus de réflexion avec ce facteur, mais on pourrait supposer qu’un rapport élevé entre les publicités et l’écran visible était un facteur négatif – un peu comme la façon dont Google prend ombrage si les publicités obscurcissent le contenu principal de la page ou sont importun.
Reliant cela aux mécanismes connus de Yandex, la mise à jour de Proxima a également pris en considération le ratio de contenu utile et publicitaire sur une page.
Pouvons-nous appliquer n’importe quel apprentissage Yandex à Google ?
Yandex et Google sont des moteurs de recherche différents, avec un certain nombre de différences, malgré les dizaines d’ingénieurs qui ont travaillé pour les deux sociétés.
En raison de cette lutte pour les talents, nous pouvons en déduire que certains de ces maîtres constructeurs et ingénieurs auront construit des choses de la même manière (pas des copies directes) et appliqué les apprentissages des itérations précédentes de leurs constructions avec leurs nouveaux employeurs.
Ce que les référenceurs russes disent de la fuite
Tout comme le monde occidental, les professionnels du référencement en Russie ont eu leur mot à dire sur la fuite à travers les différents forums Runet.
La réaction dans ces forums a été différente de SEO Twitter et Mastodon, avec un accent plus mis sur les filtres de Yandex et d’autres produits Yandex qui sont optimisés dans le cadre de campagnes d’optimisation Yandex plus larges.
Il convient également de noter qu’un certain nombre de conclusions et de constatations tirées des données correspondent à ce que le monde occidental du référencement trouve également.
Thèmes communs dans les forums de recherche russes :
- Webmasters demandant des informations sur les filtres récents, tels que Mimicry et le filtre PF mis à jour.
- L’âge et la pertinence de certains des facteurs, en raison du fait que les noms d’auteurs ne sont plus chez Yandex et des mentions de produits Yandex retirés depuis longtemps.
- Les principaux apprentissages intéressants concernent l’utilisation des données Metrika et les informations relatives au Crawler & Indexer.
- Un certain nombre de facteurs décrivent l’utilisation de DSSM, qui en théorie a été remplacé par la sortie de Palekh en 2016. Il s’agissait d’un algorithme de recherche utilisant l’apprentissage automatique, annoncé par Yandex en 2016 .
- Un débat autour de la notation ICS dans Yandex , et si oui ou non Yandex peut fournir plus de trafic vers un site et influencer ses propres facteurs en le faisant.
Les facteurs divulgués, en particulier la façon dont Yandex évalue la qualité du site, ont également fait l’objet d’un examen minutieux.
Il existe un sentiment de longue date dans la communauté SEO russe selon lequel Yandex privilégie souvent ses propres produits et services dans les résultats de recherche par rapport aux autres sites Web, et les webmasters posent des questions telles que :
Pourquoi se donnent-ils la peine de se donner tant de mal, alors qu’ils clouent leurs services en haut de la page de toute façon ?
Dans les documents vaguement traduits, ceux-ci sont appelés les sorciers ou les sorciers Yandex. Dans Google, nous appellerions ces fonctionnalités SERP (pages de résultats des moteurs de recherche) – comme Google Hotels, etc.
En octobre 2022, Kassir (un portail de billets russe) a réclamé une indemnisation de 328 millions d’euros à Yandex en raison d’une perte de revenus, causée par les «conditions discriminatoires» dans lesquelles Yandex Sorcerers a retiré la clientèle de l’entreprise privée.
Cela fait suite à un recours collectif de 2020 dans lequel plusieurs entreprises ont porté plainte auprès du FAS (Federal Antimonopoly Service) pour promotion anticoncurrentielle de leurs propres services.
source : https://www.searchenginejournal.com/yandex-data-leak/477905/


